
Data Engineer turning Risk Manager
Ju Data Engineering Weekly - Ep 64

It's in the press.
Santander’s and Ticketmaster’s Snowflake accounts probably got hacked.

An attacker using the username "rapeflake" (!!) got access to their account.

How did it happen?
It appears that MFA was not activated on the Snowflake account of … a bank!
Risk management is banks' core business, yet they failed to detect or measure the impact of using simple passwords to secure their data warehouse.
This made me wonder 🤔.
When building a data platform, we make many decisions: choose tools, design workflows, and write code.
Each of these decisions carries a certain risk.
In this article, I tried to adopt the perspective of a risk manager
We have an asset: a data platform.
The question is: what risks are we exposed to, and how can we effectively mitigate them?
1- Observability Risk
You want to know when something fails.
It seems trivial, but observability is often poorly designed.
It requires well-defined processes to monitor specific events
A lambda function that hasn't been triggered in the past x hours.
A significant drop in the volume of incoming data.
A failed scheduler run.
A message landing in a dead-letter queue.
A message nearing expiration in a dead-letter queue.
However, simply setting up alerts isn't sufficient.
You don’t want to have a Christmas tree of alerts that nobody checks.
It's crucial to classify each alert according to its criticality and to establish an appropriate resolution workflow.
A weak alerting or observability system is probably the first risk I would check when assessing a platform.
2- Data Provider Risk
A second source of risk involves external systems—specifically, the data providers to which your platform is exposed.
One very important assumption to make: data providers will fail.
Data will contain errors.
Schema will drift.
Managing the associated risk starts by knowing when the incoming data deviates.
There is a perfect tool for that: data contracts.
These contracts specify the expected data format and enable the measurement of any deviations. They act as gatekeepers for the platform.
Example of data contract (source):
orders:
description: One record per order. Includes cancelled and deleted orders.
type: table
fields:
order_id:
$ref: '#/definitions/order_id'
required: true
unique: true
primary: true
order_timestamp:
description: The business timestamp in UTC when the order was successfully registered in the source system and the payment was successful.
type: timestamp
required: true
example: "2024-09-09T08:30:00Z"
...Depending on the deviation and the source's criticality, you can choose and implement the appropriate resolution workflow to actively manage the risk of data deviations (see Section 1).
3- Data Quality Risk
While incoming data quality can be measured via data contract, the transformation results must also be tested to reduce the risk of delivering bad data.
Handling this risk can be done by:
1- Detect quality deviations
dbt test is of great help for that:

2- Deliver only tested data to the users:
Implementing the Write-Audit-Publish Pattern ensures that data undergoes testing before reaching downstream consumers.

4- Maintenance Risk
This risk becomes apparent when the platform transitions from build to run mode.
Bugs begin to surface.
Engineers spend more time resolving support cases, collecting logs, and opening S3 files.
Maintenance consumes most of the engineers' time, so no new features can be delivered.
This risk can be mitigated by considering maintenance early during development.
Take lambda functions.
Logging should be tough initially to enable easy context understanding and debugging.
And avoid this kind of log trace 😱:
“start“
"file uploaded to s3"
“start“
"file uploaded to s3"
“start“
"file uploaded to s3"The secret bullet for good logging is the Lambda powertool library.
It helps you (among others) to write logs in a structured manner and with contextual information.
The built-in logger can be passed along with your code and carry on a correlation_id to help you reconstruct the lifecycle in the logs.
In this example, the correlation_id is taken from the incoming event.
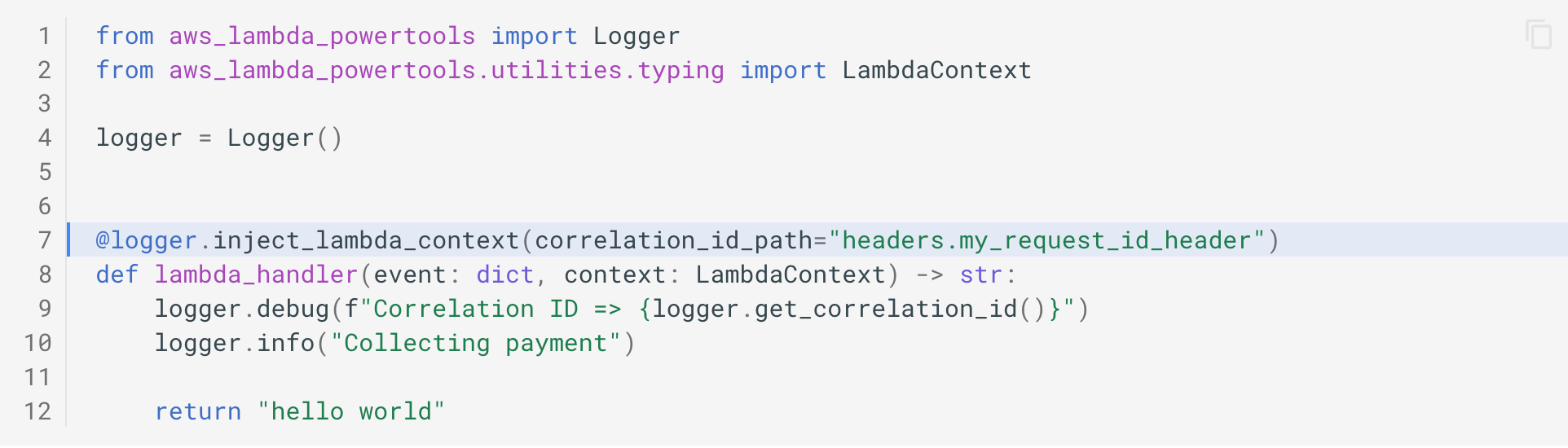
and added to the logs:

That way, you can easily track all the logs linked to this event across potentially several log groups.
This will help gather log information split across your platform and speed-up maintenance tasks.
5 - Vendor Risk
This one is quite interesting.
Nobody wants to be locked in, but all vendors want to lock you in.
Most of the time in your stack, you have to choose between opting for a SaaS or self-hosting an open-source project.
In one case, you are exposed to a vendor risk; in the other, a community risk.
Everywhere except one segment: cloud warehouses.
Iceberg and other Open Table Formats allow several engines to operate on the same copy of data.
Cloud warehouses are now rushing to integrate them.
On Monday, Snowflake announced the future release of its open-source catalog, which will allow interoperability with “AWS, Confluent Dremio, Google Cloud, Microsoft Azure, Salesforce, and more.”
Yesterday, Databricks bought Tabular.
This seems dangerous at first sight for warehouse vendors, as it makes it very easy to switch to their competitors.
I actually asked one of Snowflake's co-founders this question at a Snowflake event in Geneva at the end of last year.
His response was interesting: "We believe we have the best solution. If one day that's not the case anymore, we will have a bigger problem."
Soon, compute will come to the data (single-copy) and not vice versa.
And that’s very good news for our risk exposure.
-Ju

I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.