


Iceberg = Your AI Hedge
Ju Data Engineering Weekly - Ep 86

Bonjour!
I'm Julien, freelance data engineer based in Geneva 🇨🇭.
Every week, I research and share ideas about the data engineering craft.
Not subscribed yet?
I gave a talk last week at a meetup in Zürich.
In this post, I’ll walk you through the slides I presented and share some context around each one.
Today I wanted to talk about one of my customers: “Tumport”.

They operate in the Trumportation of goods between China and Greenland…
I had a conversation the other day with their CTO:

And he was quite worried…
Why?
Because on one hand, his business is under strong pressure to integrate AI

But on the other hand, he has a bad gut feeling.

Why?
First of all, he hates (data 😄) migrations — and for good reason:
Most of them go over budget:
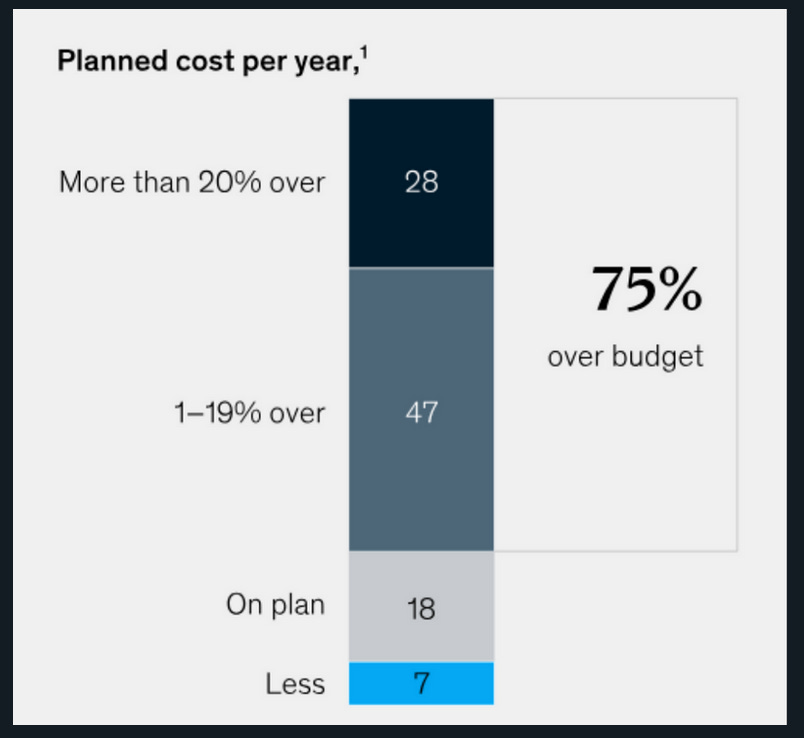
And in today’s fast-moving AI world, the market is so unstable that if he chooses a provider now…

Will he be forced to migrate again in six months?
Will the tools still exist?
Will the pricing still make sense?
But then he told me there’s something he’s even more worried about:
Big Tech is pouring massive amounts of money into AI.

But if we look at how AI is being implemented in companies, it’s still early days…
Capgemini, for example, reported that only 6% (😮) of their bookings in Q1 2025 were AI-related.

There are two possible explanations:
Companies are slow to adopt ?!?
AI does not work (yet)
So if AI fails to deliver on its promises…
Who’s going to pay the bill?
Probably us — the cloud consumers.
And cloud costs?
They’re about to explode.
The question, therefore, is how to protect yourself against all these instabilities.
This is particularly true in Europe, where tech sovereignty is becoming an increasingly important priority.
I don’t think the answer is to stop using the cloud, stop using cloud warehouses, or stop integrating AI.
The answer is to start decoupling.
Decoupling means separating where you store your data from where and how it’s used.
Or, put differently:
Choose wisely where you store your data.
Then, leverage tools only for their compute capabilities (AI, cloud warehouses).

In this situation, Open Table Formats represent an incredible opportunity to decouple your data stack.
Why?
“Traditionally,” there have been two main ways to build a data stack:

Warehouse-centered approach:
Pick one cloud data warehouse and go all-in.
✅ Great developer experience
❌ lock-in. Switching providers is painful and requires copying data around
Data lake–centered approach
Store raw Parquet files in an object storage bucket.
✅ Easy to set up and inexpensive to get started.
❌ Can quickly become chaotic (no schema enforcement/evolution)
Open Table Formats get the best of both worlds by storing metadata about your data alongside Parquet files in a cloud storage bucket.

Getting control over metadata is incredibly powerful.
From a technical perspective, it provides true “table-like” behavior over data files stored in YOUR bucket.
From a tactical standpoint, it lets you manage and control which provider has access to your data.

This means that by betting on Open Table Formats (OTF), you can choose lightweight, open-source single-node engines to process your data when appropriate.
Or, if you need to scale for a specific job, you can pick your favorite large-scale engine.

And interestingly, betting on OTF now means supporting the “in 10 years” leading compute engine.
What about the limitations?
JVM oriented
Open Table Formats are still new in terms of adoption and have mostly come from the Big Tech world.
Because of this, many tools are JVM-based, but support for Python, Rust, and Go is growing fast.
Maintenance
Controlling metadata means you have to do some maintenance to maintain good performance.
This adds complexity, but more and more managed services (like S3 Tables) handle this for you.
Catalog hosting
Finally, for Iceberg specifically, you need to host a dedicated catalog, which adds another layer of complexity.
However, providers are offering better and better managed catalog services, or you can go for the boring-catalog.

But what about AI?
Can Open Table Formats support AI workloads?
First, it’s possible to store vectors inside Parquet files—and therefore inside Iceberg.
However, when storing large vectors in Parquet, query performance can degrade.
More details why here:

This is why file formats like Lance have been created: to store large blobs more efficiently.

And guess what?
Lance has recently shared their vision for integrating with Iceberg.


In the future, depending on the workload, data will be stored in the most suitable format, while metadata will be maintained in a standardized way (OTF)—allowing any engine to efficiently query all types of data.
I find it super interesting that open table formats are rising just as the AI wave shakes the tech world.
And when European companies are sinking deeper into dependency on US tech platforms.
Open table formats feel like a lifebelt falling from the sky…
I did another interview this week on this topic with Mehdi from MotherDuck.
Check it out here:
Thanks for reading,
-Ju

Hi, great read, indeed, as always. Could you source your token marketshare by model author bar chart ? I googled for it and found no results
regards
Great read as always! Point for thought: would PyArrow (or just broadly Apache Arrow) not provide sufficient, fast handling of raw Parquet to not then require a secondary format (Lance)?