The goal is to improve data stack efficiency by running each transformation model on the best-suited engine.
For example:
Small datasets on single-node engines
Large transformations on distributed engines (Snowflake, Databricks)
However, this efficiency gain is only worthwhile if it does not involve additional complexity or engineering costs. We're aiming for a net positive experience.
Therefore, transformation frameworks like dbt and SQLMesh play a central role in this multi-engine movement to handle this additional complexity for us.
“The Dream is free, and the Hustle is sold separately” 🙂
In all my previous experiments, I constantly had to use hacks and tricks to make these frameworks work in a multi-engine setup.
That’s why I was super excited to see SQLMesh moving in that direction.
In this post, I will examine how this new SQLMesh feature brings us closer to this vision: what’s possible to build, and what gaps remain in achieving our dream architecture?
—
Thanks to Tokibo for sponsoring this post and supporting such discussions on multi-engine stacks.
Experimental Data Pipeline
Let’s have a look at the setup I used for this experiment.
The pipeline is relatively standard:
Event data is dumped into an Iceberg data lake
Metrics are computed on top of this raw data with a polars dataframe and DuckDB
Metrics are exposed in Postgres for in-app consumption
I perform computations with two query engines, Polars and DuckDB, while the data is stored in a third one: Postgres.
I will explain below the reasons that led to this design choice.
Before jumping in, let’s explain some SQLMesh concepts that make the above possible.
For full details on setup, look at the README within the repo.
SQLMesh 101
Virtual Data Environments
To understand SQLMesh’s multi-engine workflow, it’s essential to grasp its virtual data environment workflow.
SQLMesh proposes a dev workflow similar to Terraform’s plan/apply workflow.
First, you define what you want, test it in a sandbox environment (plan), and once you are satisfied with the output, you deploy it to production (by approving the plan).
To achieve this independently of the engine used, SQLMesh distinguishes between two layers:
The physical layer (physically versioned table/views)
The virtual layer (views pointing to the physical layer objects)
When the user runs the sqlmesh plan command, a physical table, and a view pointing to it are created for each model:
Each view of the virtual layer points to a physical table/view
This abstraction makes it possible to have this plan/apply development workflow:
Test your model on a copy of the production table.
sqlmesh plan dev : changes on model A are applied to a physical copy of the prod model
Deploy to production by making the production view point to this new table.
Each time you update your model, a new physically versioned table/view is created, and the associated view of the virtual layer is updated to point to this new table.
sqlmesh plan: model A’s view points now to physical table v2
Gateways
Let’s now explain how connection profiles are handled in SQLMesh, which is key in a multi-engine setup.
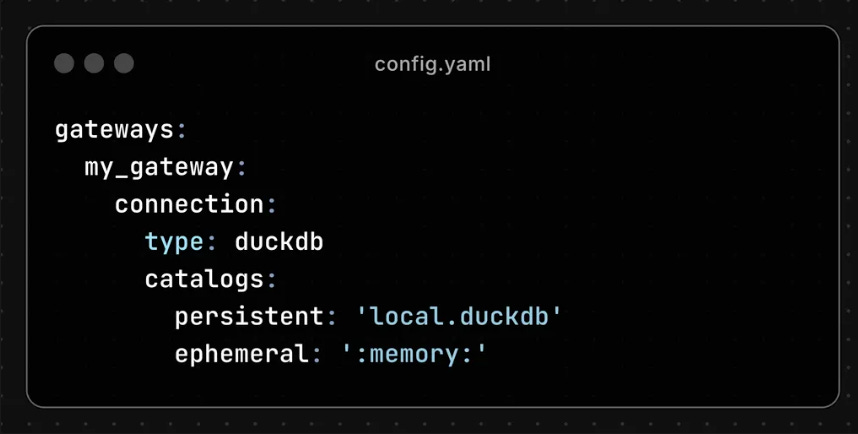
SQLMesh connection profiles are called gateways and are defined in the project’s config.yaml.
Each gateway can be configured to read/write data to various ‘catalogs’.
In the case of DuckDB, a catalog can be, for example, either an in-memory instance or a DuckDB file.
SQLMesh & Multi-engine
To leverage the multi-engine feature of SQLMesh, you need to define:
A default gateway exposing a catalog where all models will be materialized as tables/views.
Other gateways that can write to this default catalog.
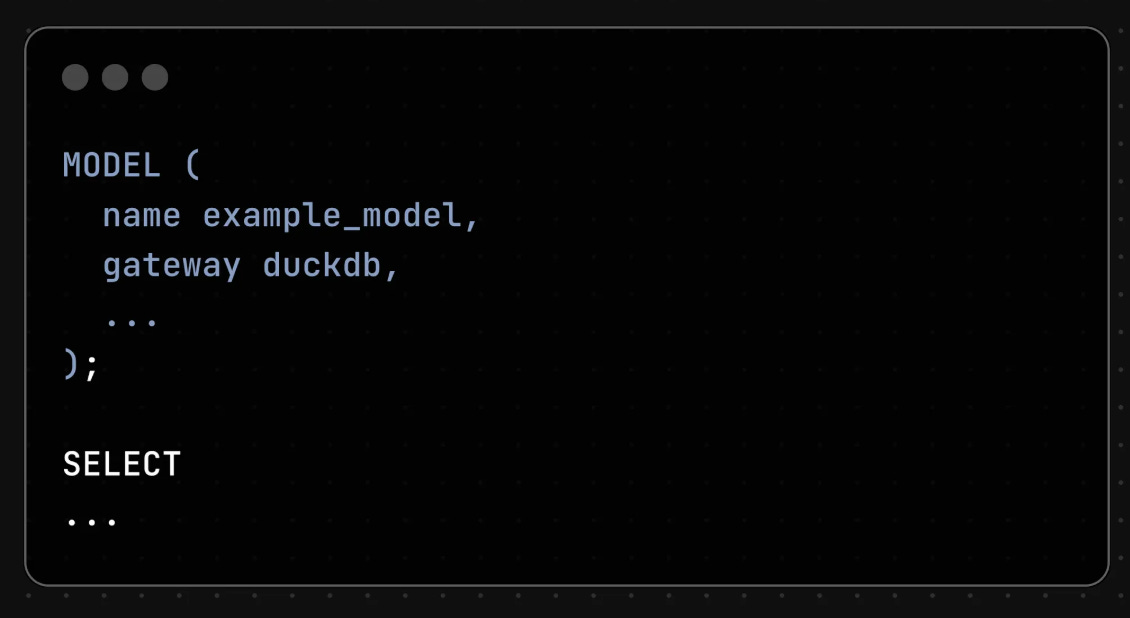
The user can then specify a gateway attribute for each model:
What happens then?
This model will be computed by the specified gateway and stored in the project’s default gateway:
Example of catalog integration with Postgres and DuckDB
There are two main limitations to this design:
All models must be materialized in a single gateway.
It only supports use cases where gateways can write to a shared catalog. Examples:
DuckDB on a Postgres database → The binding is done via the ATTACH command.
Spark, Trino, or any query engines that can read/write to a shared iceberg catalog
Read/write support for Iceberg catalogs is still in its early stages, but the number of use cases will likely (and hopefully 🤞🏻) grow in the coming months as engines like DuckDB add Iceberg write support.
Let’s run it!
Bringing data in
I use a vanilla Python script that generates and writes event data to an Iceberg table (Glue catalog) using PyIceberg.
This script continuously adds events to the table.
Let’s now see how we can perform batch transformations on top of this landing table with SQLMesh using two engines: Polars and DuckDB.
Model 1: Aggregate event with Polars
As the volume of row events can grow significantly, I perform an initial transformation where events are aggregated into 5-minute time buckets.
Polars is an excellent tool for this pre-transformation, as it enables logic unit testing and lazy execution.
To run Polars inside SQLMesh, I leverage the Python models feature. Python models are defined by adding the @model decorator to a function returning a DataFrame.
SQLMesh then automatically ingests the DataFrame through the chosen gateway.
I like the SQLMesh overlay on top of my Polars code.
First, it allowed me to add data tests (”audits”) right out of the box.
Then, its approach to incremental processing is quite interesting: it uses an interval-based method.
In my case, I wanted to aggregate events every 5 minutes, so I set the model’s kind to SQLMesh INCREMENTAL_BY_TIME_RANGE and the cron attribute to */5 * * * *.
Each time I run SQLMesh, it counts the number of missing intervals since the last run and automatically adjusts the model’s start and end inputs.
I like how this forces you to think about partitions when designing your model, making future backfilling much easier.
Improvements
In the current model, I return a dataframe, and SQLMesh handles the write to Postgres.
Ideally, I would like to store the output in Iceberg instead of Postgres.
To do this, we would need a model gateway that can write to a shared Iceberg catalog (Glue in this project).
Among the engines supported by SQLMesh, Spark and Athena (Trino) could potentially do it (DuckDB doesn’t natively support writing to Iceberg).
Another possibility would be to use PyIceberg in the model itself to write to Iceberg:
While this is doable, it would be quite clunky. The data would live outside of the SQLMesh workflow explained above, and we would lose many of SQLMesh's features (virtual data environment, audit).
Model 2: Metric computation in SQL
The goal of the second model is to perform metric computation in SQL.
Data analysts usually define these metrics, and therefore, SQL seems to be a better fit.
In this example pipeline, I leverage the multi-engine feature and compute the metric in DuckDB.
The gateway setup is similar to the one mentioned above, with a catalog pointing to the default Postgres gateway:
The SQL model looks like this:
This model has its cron set to hourly so it will be refreshed every hour. Similar to the Python model, I like how easy it is to define a frequency, and SQLMesh handles the cron ‘hell’ for me.
I wondered, though, how people orchestrate this in production.
Answer: pick the model with the lowest frequency and trigger sqlmesh run at this frequency if using open source. It'll ensure that only what's necessary is run since it tracks the state of past runs.
Improvement
Like the other model, I would ideally like to persist data in Iceberg.
There are two ways this could be done:
Use a DuckDB gateway; however, DuckDB cannot write to Iceberg easily
Leverage SQLMesh’s multi-engine feature and ATTACH DuckDB to another engine that would handle reading/writing to Iceberg. Athena is a great candidate for that, but unfortunately, we cannot “ATTACH” DuckDB to Athena.
Conclusion and Envisioning the Future
With this new feature, SQLMesh pushes the limits of what is possible to build in multi-engine setups.
Even though it has some limitations and it’s still too early to build 100% on top of Iceberg, it gives a good sense of what is possible when such interoperability is unlocked.
In this experiment, I mixed two engines with different strengths:
Polars for data engineering-friendly dataframe transformations
DuckDB for analyst-friendly SQL models
Having them orchestrated in the same framework allows various data team members to collaborate using their favorite tools and benefit from end-to-end lineage and standardized testing.
With this multi-engine feature, SQLMesh is building the foundation for what would be my target architecture:
In this setup, all the models are materialized to Iceberg, with only the last layer materialized to Postgres.
To make this setup practical, it would require:
Iceberg native read/write support across all engines with more “catalogs” integrations (the feeling of ATTACH DuckDB everywhere^^)
The ability to materialize models in various engines by SQLMesh (this design choice is up for debate because then Iceberg wouldn't be the source of truth).
Building a data stack is hard—too many moving pieces, too little time.
That’s where Boring Data comes in.
I’ve created a data stack onboarding package that combines ready-to-use templates with hand-on workshops, empowering your team to quickly and confidently build your stack.
Interested?
Check out boringdata.io or reply to this email—I’d be happy to walk you through our templates and workshops.
I would be grateful if you could help me to improve this newsletter. Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.
Thanks for reading Ju Data Engineering Newsletter! Subscribe for free to receive new posts and support my work.
It's an open-source multi-engine query router in rust that give you one front door for SQL clients — Trino, PostgreSQL, MySQL, and Flight on the wire; Trino, DuckDB, StarRocks, and more behind it. Routing by rules, translate dialects with sqlglot, and run with metrics and queueing, and more features. I think it can be useful in this context :)
This is really interesting. DuckDB now supports the Iceberg Catalog for S3 tables which is a great move forward. It would be fantastic if they could soon incorporate write capabilities alongside expanded Iceberg Catalog support.





















Did you check out https://queryflux.dev/?
GitHub: https://github.com/lakeops-org/queryflux/tree/main
It's an open-source multi-engine query router in rust that give you one front door for SQL clients — Trino, PostgreSQL, MySQL, and Flight on the wire; Trino, DuckDB, StarRocks, and more behind it. Routing by rules, translate dialects with sqlglot, and run with metrics and queueing, and more features. I think it can be useful in this context :)
This is really interesting. DuckDB now supports the Iceberg Catalog for S3 tables which is a great move forward. It would be fantastic if they could soon incorporate write capabilities alongside expanded Iceberg Catalog support.